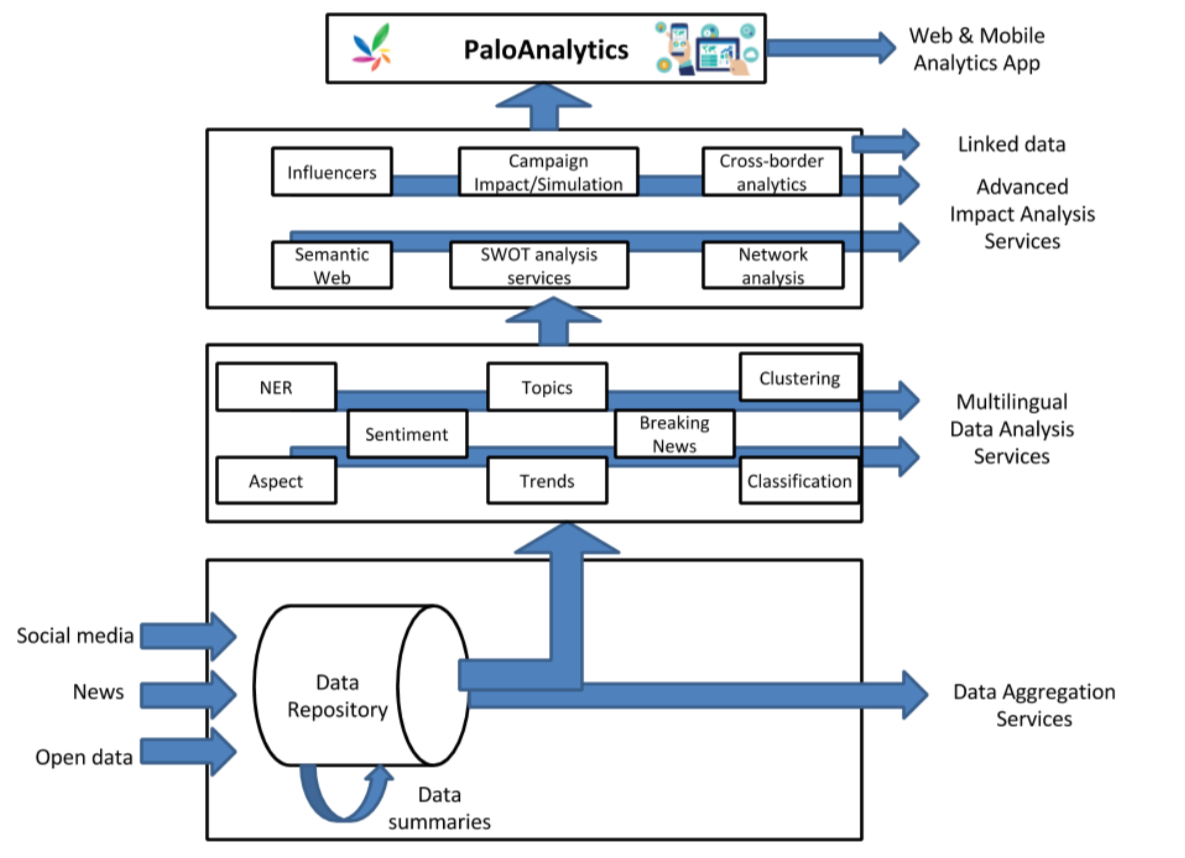
To implement the new service, a number of software tiles will be designed and developed :
- analyzing multilingual content posted on news sites, social networks as well as on open data,
- exporting knowledge and information about products / companies and their individual characteristics that are commented on,
- analyzing their sources, their influence and the trends they shape and
- helping service subscribers evaluate the image of the business and its products in different markets with different habits and cultures to tailor marketing and communication strategies accordingly.
Neural Networks
For unified multilingual content management, deep neural networks with shared secret layers that have been successfully used in multilingual knowledge transfer models for SpeechToText applications as well as recent deep learning implementations for extracting emotion for multiple product features from multilingual texts will be used.
Language Agnostic
English will be used as a single reference language for all individual languages and the possibility of simultaneous automatic translation into multiple languages using mechanical learning will be investigated (Firat et al., 2016). Due to the absence of parallel text bodies covering all source cases covered by the new platform, the development of knowledge mining techniques from multilingual text bodies is not directly feasible. Language agnostic techniques are not sufficient to address the problem, and for the needs of the project, the integration of an automatic translation mechanism into the various stages of the knowledge mining process will be studied.
Business Data
Finally, for the analysis of business data and reports, algorithms will be designed for the automatic extraction of relationships between enterprises.
As far as the analysis of business influence on social networks and the formation of public opinion, which is directly related to the strategic positioning of enterprises, models of analysis of the dynamics of opinion in social media will be used and will be extended to incorporate the polarity opinion and the confidence in the social networks.
Imprinting of Extracting Knowledge
Finally, with regard to capturing extracted knowledge and linking it to open data sources, techniques such as Association Link Networks will be used to extract semantic links between entities extracted from news and other texts, and to handle the huge amount of data the whole solution will integrate distributed architectures and platforms (Apache Spark, ELK stack, etc.) to address the escalation issues.
Full Development Stack
This will develop a full development stack based on multilingual content from news sites, open data sources and social media. The services of this stack are expected to attract third-party companies, start-ups, public bodies and researchers to develop new ways of managing business data from the sources that PON incorporates, setting new business models on them, multiplying the benefits for the company and at the same time maximizing the impact of the proposed solutions on the scientific and business community.